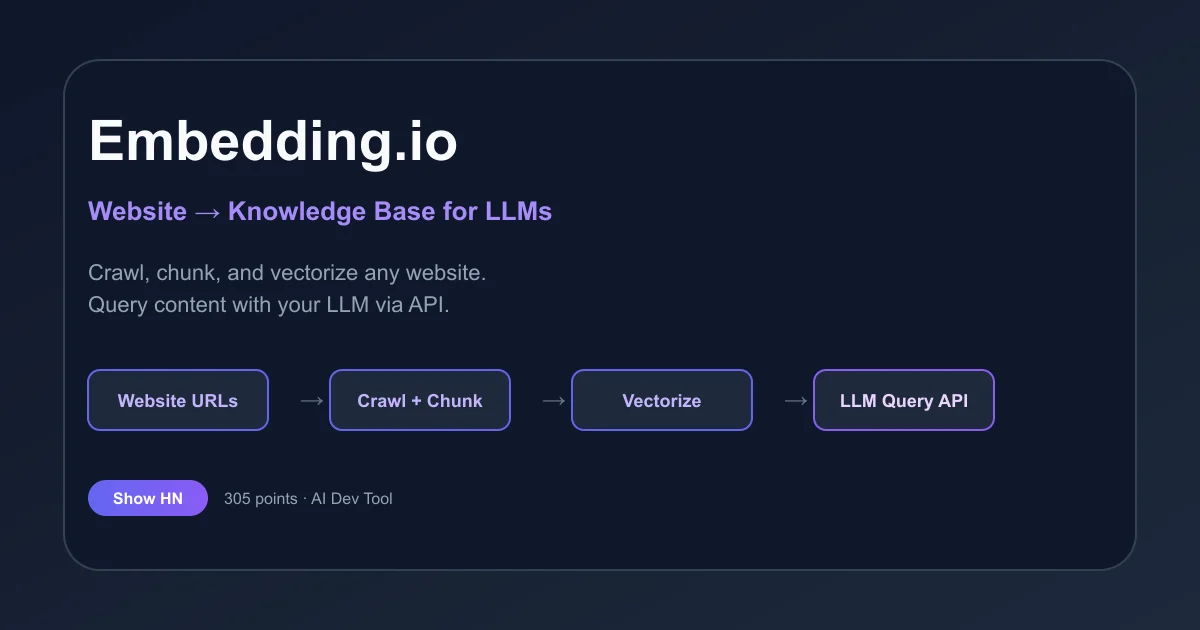
Embedding.io - Turn Websites Into Knowledge Bases for LLMs
Crawl, chunk, and vectorize any website into a queryable knowledge base. REST API with collections, scheduled updates, and built-in RAG for LLM applications.
TL;DR
TL;DR: Embedding.io is a hosted API that crawls, chunks, and vectorizes any website into a queryable knowledge base, removing the need to build your own RAG ingestion pipeline.
Source and Accuracy Notes
- Official site: embedding.io
- Documentation: embedding.io/docs
- HN launch: Show HN – 305 points (July 2024)
- API base:
https://api.embedding.io/v0/
What Is Embedding.io?
Embedding.io solves a recurring pain in LLM application development: getting website content into a vector store so your AI can reason over it. Instead of writing crawlers, building chunking logic, managing embeddings, and scheduling re-indexing, you point Embedding.io at a set of URLs or domains and query the result through a REST API.
The core abstraction is the Collection — a named group of web pages or entire domains that are crawled, chunked, and vectorized together. You create a collection, add domains to it, and query it. The service handles content extraction, text chunking, embedding generation, and periodic re-crawling to keep the knowledge base fresh.
# Create a collection
curl --request POST \
--url https://api.embedding.io/v0/collections \
--header 'Authorization: Bearer YOUR_TOKEN' \
--json '{ "name": "Health References" }'How the Pipeline Works
Step 1: Create a Collection
Collections are containers for related web content. You can have up to 5 on the Hobby plan, 10 on Startup, and unlimited on Enterprise.
curl --request POST \
--url https://api.embedding.io/v0/collections \
--header 'Authorization: Bearer YOUR_TOKEN' \
--json '{ "name": "Product Documentation" }'The API returns a collection ID (col_xxxxx) that you use for all subsequent operations.
Step 2: Ingest Content
Add domains or specific URLs to your collection. Embedding.io handles the rest — crawling, content extraction, chunking, and vectorization.
curl --request POST \
--url https://api.embedding.io/v0/collections/col_xxxxx/websites \
--header 'Authorization: Bearer YOUR_TOKEN' \
--json '{
"domains": [
"https://docs.example.com/",
"https://blog.example.com/"
]
}'No sitemap required — the crawler discovers pages from any publicly accessible URL.
Step 3: Query Your Collection
Once content is ingested, query it with natural language. The API performs semantic search over the vectorized content and returns relevant chunks.
curl --request POST \
--url https://api.embedding.io/v0/query \
--header 'Authorization: Bearer YOUR_TOKEN' \
--json '{
"collection": "col_xxxxx",
"query": "How do I configure the deployment pipeline?"
}'Step 4: Automatic Updates
Content stays fresh automatically based on your plan tier:
| Plan | Update Frequency | |---|---| | Free (500 credits) | Monthly | | Hobby ($20/mo) | Weekly | | Startup ($100/mo) | Daily | | Enterprise | Hourly |
Each page update consumes one credit, same as initial ingestion.
Deeper Analysis
What Makes It Different From DIY RAG
Building your own website-to-vector-store pipeline typically involves:
URL List → Crawler (Playwright/Scrapy)
→ Content Extractor (readability/trafilatura)
→ Chunker (LangChain text splitter)
→ Embedding Model (OpenAI/local)
→ Vector Store (Pinecone/Weaviate/pgvector)
→ Query API (custom FastAPI/Express)
→ Scheduled Re-crawl (cron + diff detection)That is seven components to build, deploy, and maintain. Embedding.io collapses them into a single API call. The trade-off is vendor dependency and per-page costs — but for teams that want to focus on the LLM application layer rather than infrastructure, it is a significant time saver.
Credit System Explained
A credit equals one page ingested or one page updated. If you add 100 pages to a collection on the Hobby plan (2,000 credits), you have enough for 20 weekly refresh cycles before needing to top up. Pages that do not change between crawls do not consume credits — only pages with new or modified content trigger a re-embedding.
Public Collections
Embedding.io maintains several pre-built public collections you can query without an account:
- WordPress Documentation — full WordPress developer docs
- Laravel 11.x Documentation — complete Laravel framework reference
- Embedding.io Documentation — their own API docs (meta, but useful)
- Paul Graham Essays — the complete PG essay archive
- Patrick McKenzie (patio11) — Kalzumeus blog archive
- Tim Ferriss — blog content
These are useful for prototyping RAG applications without spending credits on ingestion.
Practical Evaluation Checklist
- [ ] Sign up at app.embedding.io/register — free tier gives 500 credits
- [ ] Create a collection via API or web interface
- [ ] Add 3-5 domains relevant to your use case
- [ ] Wait for initial ingestion (depends on site size)
- [ ] Test queries via the API — check relevance and chunk quality
- [ ] Evaluate update frequency against your content freshness needs
- [ ] Compare credit burn rate against your expected query volume
- [ ] Test with JS-heavy SPAs — some sites may not render fully in the crawler
Security Notes
- API authentication uses Bearer tokens — treat them like passwords
- Content is crawled from publicly accessible URLs only — no authenticated crawling
- API traffic is HTTPS-only
- Review what content you expose via public collections before publishing
- Rate limits apply per plan tier — check docs for current thresholds
- Enterprise plan offers custom crawlers for sites with auth requirements
FAQ
Q: Does Embedding.io require a sitemap? A: No. The crawler discovers pages from any publicly accessible URL without needing a sitemap.xml file.
Q: What counts as a credit? A: One credit is consumed per page ingested initially, and one credit per page when its content changes during a scheduled update. Unchanged pages do not consume credits.
Q: Can I use Embedding.io with my own LLM? A: Yes. The query API returns raw text chunks — you pass them to any LLM (OpenAI, Anthropic, local models) as context in your prompt. Embedding.io handles retrieval, not generation.
Q: How does content extraction handle JavaScript-rendered pages? A: The crawler uses a headless browser to render JavaScript before extracting content. However, heavily gated or login-required content may not be fully accessible on lower-tier plans.
Q: Is there a self-hosted option? A: No. Embedding.io is a hosted SaaS product only. The Enterprise plan offers custom crawler configurations but the infrastructure remains managed by Embedding.io.
Conclusion
Embedding.io fills a real gap in the LLM tooling stack. If you have ever spent a weekend wiring up a crawler, a chunker, and a vector store just to ask questions about a documentation site, you understand the problem. The service is not cheap at scale ($100/mo for daily updates on 20K pages), but the free tier is generous enough to evaluate, and the API is simple enough to integrate in under an hour.
For RAG-heavy applications — customer support bots, internal knowledge search, documentation assistants — Embedding.io removes an entire category of infrastructure work. The public collections are a nice touch for quick prototyping. Worth trying if your next project involves “ask questions about this website.”
Related Posts
dev-tools
Raindrop Workshop Agent Debugging Guide
Set up Raindrop Workshop for local agent traces, tool-call debugging, replay workflows, SQLite storage, instrumentation, and eval repair loops.
5/28/2026
dev-tools
Superset – Orchestrate 100+ Coding Agents in Parallel
Superset runs Claude Code, Codex, Cursor, and other AI coding agents simultaneously in parallel workspaces. Orchestrate agents, automated workflows, and code.
5/28/2026
dev-tools
Frigade – Build Product Onboarding That Actually Works
Frigade is a developer tool that makes it easy to build polished, interactive product onboarding flows without the usual headache.
5/28/2026