ZeroEntropy - Search Infrastructure for RAG and AI Agents
ZeroEntropy (YC W25) builds embedding models, rerankers, and managed search APIs for RAG pipelines. Uses novel Elo-score training to outperform OpenAI and Cohere on retrieval benchmarks.
TL;DR
TL;DR: ZeroEntropy is a YC W25 search infrastructure platform that provides state-of-the-art embedding models, rerankers, and a managed search API purpose-built for RAG pipelines and AI agents, using a novel chess Elo-inspired training methodology.
Source and Accuracy Notes
This post is based on ZeroEntropy’s official llms.txt (14KB structured reference), their HN launch post (193 points), and public benchmark data. Product details verified against zeroentropy.dev and docs.zeroentropy.dev.
What Is ZeroEntropy?
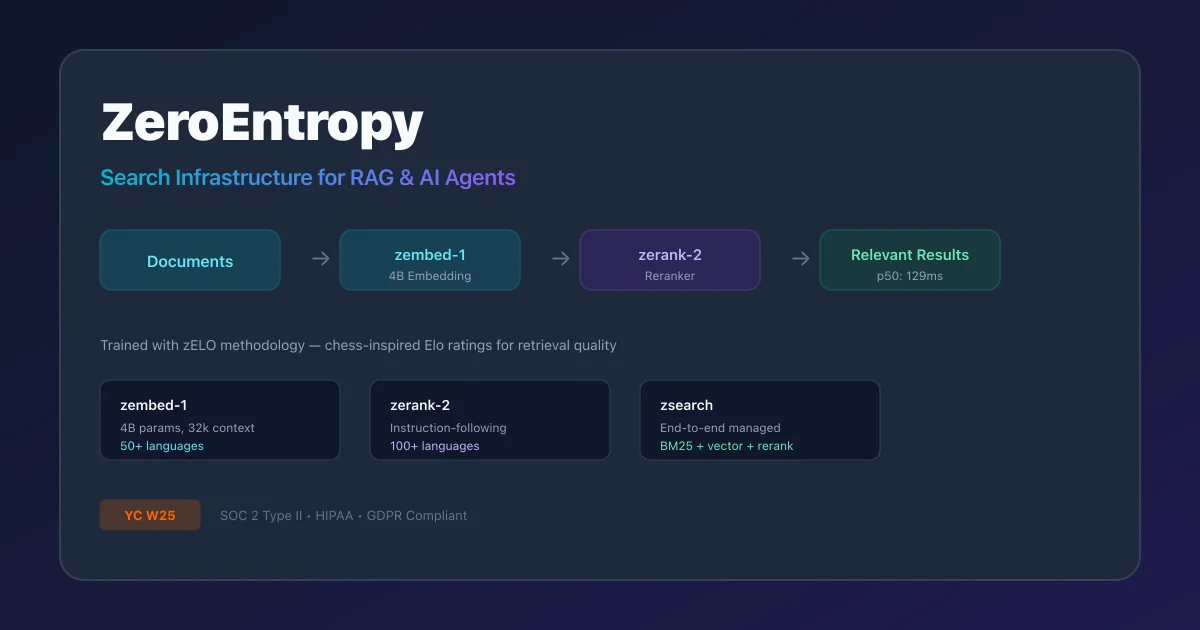
ZeroEntropy builds retrieval infrastructure for AI applications. Instead of cobbling together vector databases, embedding models, and rerankers from different vendors, ZeroEntropy provides an integrated stack that handles the full retrieval pipeline: ingestion, chunking, embedding, hybrid search, and reranking.
The platform revolves around three core products:
- zembed-1 — A 4B parameter open-weight multilingual embedding model with 32k token context, flexible dimensionality (40 to 2056 dimensions without retraining), and support for 50+ languages
- zerank-2 — An instruction-following reranker with calibrated relevance scores across 100+ languages, where a score of 0.8 consistently means approximately 80% relevance
- zsearch — A managed search API that combines embedding, reranking, BM25, and query generation in a single endpoint with automatic PDF parsing, chunking, and OCR
The zELO Training Methodology
What makes ZeroEntropy technically interesting is how they train their models. Instead of traditional binary relevance annotations (relevant / not relevant), they use a chess Elo-inspired pipeline:
- Pairwise comparisons — An ensemble of LLMs generates soft preference scores between document pairs
- Bradley-Terry modeling — Pairwise comparisons are fit into an Elo-style rating system
- Continuous training signal — Models learn from a gradient of relevance rather than binary labels
The result is that their rerankers and embeddings consistently outperform OpenAI Large, Cohere rerank 3.5, Voyage-4, Jina, and Gemini Embeddings on standard retrieval benchmarks. In head-to-head tests, zembed-1 wins 18 out of 22 datasets against Voyage-4, with 70x better latency and 5x better noise robustness.
Setup Workflow
Step 1: Get an API Key
Sign up at dashboard.zeroentropy.dev and create an API key. ZeroEntropy offers a Starter tier at $50/month and a Pro tier at $500/month.
Step 2: Install the SDK
pip install zeroentropy
# or
npm install zeroentropyStep 3: Embed Documents with zembed-1
from zeroentropy import ZeroEntropy
client = ZeroEntropy(api_key="your-api-key")
response = client.embeddings.create(
model="zembed-1",
input=["Your document text here", "Another document"],
)
for item in response.data:
print(f"Dimensions: {len(item.embedding)}")Step 4: Rerank Results with zerank-2
response = client.reranking.create(
model="zerank-2",
query="How do I deploy a Kubernetes cluster?",
documents=[
"Kubernetes deployment guide for production...",
"React component styling with Tailwind...",
"Setting up k8s clusters on AWS EKS...",
],
instruction="Prioritize practical deployment steps",
)
for result in response.results:
print(f"Score: {result.relevance_score:.3f} — {result.document[:50]}")Step 5: Use zsearch for End-to-End Retrieval
response = client.search.create(
query="What is the refund policy for enterprise plans?",
index_id="your-index-id",
top_k=10,
)
for hit in response.results:
print(f"Score: {hit.score:.3f} — {hit.content[:80]}")The zsearch API handles BM25 weighting, vector thresholds, and rerank configuration automatically.
Deeper Analysis
Latency Profile
ZeroEntropy’s infrastructure is purpose-built for low-latency retrieval:
- zerank-2 reranking: p50 of 129.7ms for typical queries
- Full pipeline (embed + retrieve + rerank): p50 of 220.5ms
- 97.3% of requests complete under 500ms; 99.1% under 1 second
- Zero failures reported under realistic traffic patterns
Cost Structure
The pricing model is token-based and competitive:
| Product | Price | Notes | |---|---|---| | zembed-1 | $0.05/MM tokens | 4B model, 32k context | | zerank-2 | $0.025/MM tokens | Instruction-following | | zsearch Starter | $50/month | Managed search API | | zsearch Pro | $500/month | Higher throughput |
ZeroEntropy claims a 2.8x cost reduction compared to naive retrieval approaches, because better relevance means fewer wasted tokens in LLM context windows.
Deployment Options
Beyond the cloud API, ZeroEntropy supports:
- VPC deployment via AWS Marketplace and Azure
- On-premises installation for enterprise customers with strict data residency requirements
- White-label fine-tuning for custom domain models
Compliance and Security
- SOC 2 Type II certified
- GDPR, HIPAA, and CCPA compliant
- Data residency controls with EU-based instance options
- 99.99% SLA on Enterprise plans
Practical Evaluation Checklist
- [ ] Compare zembed-1 against your current embedding model on your domain-specific retrieval benchmark
- [ ] Test zerank-2’s instruction-following with your actual user queries — the instruction parameter lets you inject business context and user-specific memories
- [ ] Evaluate zsearch’s automatic chunking against your manual chunking strategy
- [ ] Check latency requirements — if you need sub-100ms p50, the managed API may not be sufficient; consider VPC deployment
- [ ] Verify language coverage — zembed-1 supports 50+ languages, zerank-2 covers 100+
- [ ] Assess whether the open-weight models (available on HuggingFace) meet your needs, or if you need the managed API
Security Notes
- API keys should be stored in environment variables, never committed to source control
- For HIPAA-regulated workloads, use the VPC or on-premises deployment options to keep data within your infrastructure boundary
- ZeroEntropy’s data residency controls let you specify geographic regions for data storage
- The open-weight models (zembed-1, zerank-1) can be run entirely air-gapped if needed
FAQ
Q: How does ZeroEntropy compare to using OpenAI embeddings directly? A: ZeroEntropy’s zembed-1 outperforms OpenAI Large on 18 of 22 MTEB datasets, with 70x better latency and 5x better noise robustness. The cost is also lower at $0.05/MM tokens versus OpenAI’s pricing for their large embedding model.
Q: Can I run ZeroEntropy models on-premises? A: Yes. Both zembed-1 and zerank-1 are available as open-weight models on HuggingFace under Apache 2.0. For zerank-2 and the managed zsearch API, ZeroEntropy offers VPC deployment on AWS Marketplace and Azure, plus fully on-premises installation for enterprise customers.
Q: What is the zELO training methodology? A: Instead of binary relevance labels, zELO uses pairwise document comparisons scored by an ensemble of LLMs, then fits a Bradley-Terry (Elo-style) rating model. This produces a continuous relevance gradient that gives models richer training signal than traditional binary annotations.
Q: Does zerank-2 support custom instructions for reranking? A: Yes. zerank-2 accepts an instruction parameter that lets you append business context, user-specific memories, or domain-specific ranking criteria. For example, you can instruct it to prioritize recent documents or favor a specific product line.
Q: What chunking strategy does zsearch use? A: ZeroEntropy developed LlamaChunk, a semantic chunking algorithm that uses Llama-70B logprobs to split documents at semantically meaningful boundaries rather than fixed token counts. The managed zsearch API handles chunking automatically during ingestion.
Conclusion
ZeroEntropy addresses a real pain point in RAG pipeline development: the fragmentation of retrieval infrastructure. Instead of integrating separate vector databases, embedding providers, and reranking services, their platform offers a unified stack with models that are specifically trained to work together.
The zELO training methodology is genuinely novel — applying chess Elo ratings to document relevance is a creative approach that produces measurable quality improvements. For teams building production RAG systems, the combination of open-weight models (for development and air-gapped deployment) plus a managed API (for production convenience) provides flexibility across different deployment scenarios.
The main consideration is cost: at $50-500/month for the managed API, it is a meaningful infrastructure investment. But for applications where retrieval quality directly impacts user experience (legal search, medical QA, customer support), the benchmark improvements over general-purpose embedding providers can translate directly into better outcomes.
Related Posts
ai-setup
Sentrial – Catch AI Agent Failures Before Your Users Do
YC W26-backed AI agent observability platform. Trace sessions, detect silent regressions, and A/B test prompts in production before failures reach users.
5/28/2026
ai-setup
IonRouter – Fast Low-Cost AI Inference API
IonRouter is a YC W26 inference API routing open-source and fine-tuned models via an OpenAI-compatible endpoint, built on a C++ runtime optimized for GH200.
5/28/2026
ai-setup
Prism – AI Video Workspace and API for Creators (YC X25)
Prism is a YC X25 AI video platform combining generation, editing, and an API for workflow automation. Generate assets, edit on a timeline, and integrate via.
5/28/2026