MovingLake - Real-Time Data Connectors for Any API
MovingLake is a YC S22 data integration platform that combines polling, webhooks, websockets, REST, GraphQL, and SOAP into a single fan-out stream for any backend.
TL;DR
TL;DR: MovingLake is a YC S22 real-time data integration service that turns the usual mix of polling, webhooks, websockets, REST, GraphQL, and SOAP endpoints into a single fan-out stream you can route to any backend, warehouse, or CRM in near real time.
Source and Accuracy Notes
- Official site: movinglake.com
- App console: app.movinglake.com
- HN launch: Launch HN: MovingLake (YC S22) - Oct 2022 (132 points, 60 comments)
- Founders: Andres and Edgar (CTO background at Series B startups in Latam, ex-big-tech engineers)
- Testimonial on the homepage: Miguel Magos, VP of Data at Casai
The product has been live since 2022 and the official site is still active with the same connector catalog positioning. Pricing is a flat monthly fee rather than per-event or per-row, which the founders call out as deliberate.
What Is MovingLake?
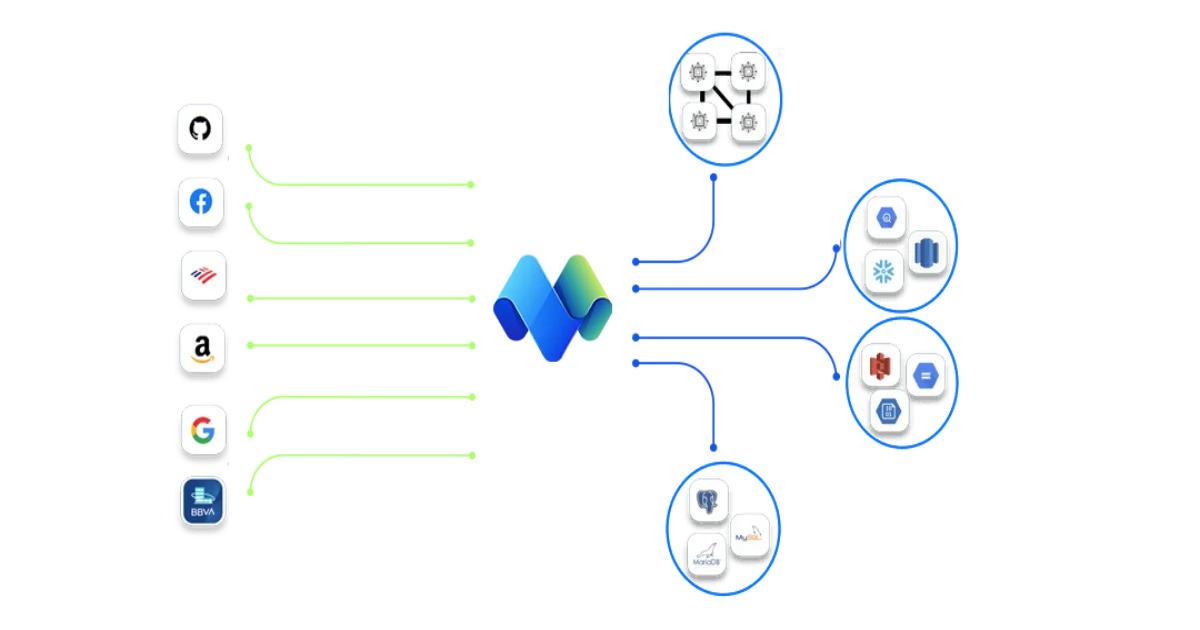
MovingLake is a managed pull-to-push integration service. You point it at a source API, it subscribes to whatever the API supports (webhooks first, websockets if offered, polling as a fallback), and it normalizes everything into a single event stream that you can fan out to any number of destinations: production databases, ERPs, CRMs, data warehouses, datalakes, or message queues.
The mental model is: instead of writing N custom scripts to move data from M sources to K destinations, you configure each source once and then bind as many destinations as you want for the same price.
The current source catalog includes payments (Stripe, BBVA), commerce (Amazon, Shopify, Facebook), productivity (Google Workspace, Notion), dev tools (GitHub, Bitbucket), communications (Whatsapp, Telegram), and a long tail of niche APIs. On the destination side you get Postgres, MySQL, Snowflake, BigQuery, Kafka, S3, webhooks, and a few ERP connectors.
Why MovingLake?
Most data integration tools force you to choose between two failure modes:
- The polling-only tool keeps your data fresh-ish (every 5–15 minutes), burns through API rate limits, and produces noisy duplicate events when retries overlap.
- The webhook-only tool gives you real-time delivery but only for the few sources that actually publish webhooks. The other 80% of your stack still needs polling somewhere.
MovingLake picks the right transport per source and merges the streams. If the API supports webhooks, those are used. If it only supports websockets, those are used. If it only has GET endpoints, the platform polls as fast as the rate limit allows. To the consumer, you just get a single replayable stream with built-in retry, back-off, jitter, and a dead-letter queue.
The reverse direction works the same way. CDC plugins watch your databases and stream change events to any destination, and the platform includes an automatic JSON-to-SQL converter with schema evolution, so a destination table gains new columns as the source schema changes without manual intervention.
Setup Workflow
Step 1: Pick a source
The connector catalog lives at movinglake.com/sources. Each entry lists supported endpoints, the transport the platform will use, and any rate-limit caveats. For this walkthrough, Stripe is a clean example because the API exposes webhooks for nearly every event, but the catalog includes hundreds of options.
# After signing in, the "Create Source" flow gives you a list.
# You can also browse the full catalog from the CLI if you have an API key:
curl -H "Authorization: Bearer $MOVINGLAKE_KEY" \
https://api.movinglake.com/v1/sourcesStep 2: Map the entities you care about
For each source you select the entities and endpoints to sync. The platform pre-fills webhook bindings if the API supports them, and exposes polling frequency as an override. The default is to use whatever the API rate limit allows while still staying under the published quota.
A practical configuration for Stripe looks like this:
| Entity | Transport | Default frequency | Override |
| --- | --- | --- | --- |
| charge | Webhook | real-time | n/a |
| customer | Polling + Webhook | 1 minute | 30s |
| invoice | Webhook | real-time | n/a |
| payout | Polling | 5 minutes | 1 minute |
Step 3: Bind destinations
Destinations are bound per source, and the same source can fan out to many. Bindings are configured in the same UI:
# Bind a Stripe source to three destinations
curl -X POST -H "Authorization: Bearer $MOVINGLAKE_KEY" \
-H "Content-Type: application/json" \
-d '{
"source_id": "src_stripe_8x2k",
"destinations": [
{ "type": "postgres", "url": "$DATABASE_URL", "schema": "stripe_live" },
{ "type": "snowflake", "account": "xy12345", "database": "RAW", "schema": "STRIPE" },
{ "type": "webhook", "url": "https://api.yourcompany.com/movinglake" }
]
}' \
https://api.movinglake.com/v1/destinationsThe Postgres destination writes events directly into the configured schema with a movinglake-managed table per entity. The Snowflake destination streams into a Snowpipe. The webhook destination forwards each event as a POST with HMAC signing.
Step 4: Subscribe to the stream
For low-latency use cases, the platform also exposes a websocket or webhook destination so that downstream services can subscribe to events without round-tripping through a database. Webhook destinations support optional HMAC signing, retry, and dead-letter routing:
# HMAC verification on the receiving side (Node.js example)
const crypto = require('crypto');
const sig = req.headers['x-movinglake-signature'];
const expected = crypto.createHmac('sha256', process.env.MOVINGLAKE_SECRET)
.update(req.rawBody)
.digest('hex');
if (sig !== expected) return res.status(401).end();Step 5: Monitor the pipeline
The dashboard at app.movinglake.com shows source health, event counts, retry queues, and per-destination lag. The customer quote on the homepage (Casai) is a useful signal: the team reports drift between source APIs and the destination database is “never more than a minute or so” under normal load.
Deeper Analysis
What MovingLake gets right
- Transport flexibility is built in, not bolted on. Many competitors charge extra for websockets, or skip them entirely and force polling. MovingLake picks the right transport per API, which matters when you have a heterogeneous source list.
- Fan-out pricing. The flat monthly fee is genuinely fan-out: bind ten destinations to one source and you pay the same as binding one. Most per-event tools price by total throughput, which means a single high-volume source can make fan-out prohibitively expensive.
- Replay and dead-letter behavior. Failed events are retried with back-off and jitter, and the platform supports an optional deduplication layer so a retried event is never delivered twice. This is closer to enterprise integration tooling (MuleSoft, Workato) than to lightweight iPaaS.
- Schema evolution. When a source API ships a new field, the destination table grows automatically. This removes a class of silent failures where the source emits a new attribute and the destination silently drops it.
What to watch out for
- Booking-required sales flow. As of the latest snapshot of the site, the “Get Started” CTA points to a “Book a demo” form, not a self-serve signup. If you want to evaluate quickly, you may need to wait for a sales reply.
- Niche destination coverage. The destination list is solid for warehouses and databases, but if you need an unusual ERP or a custom internal system, you will likely end up on the webhook destination and writing your own consumer.
- Vendor lock-in for transformations. Like most integration tools, transformations live inside the platform. If you need to migrate off later, you can replay raw events into a new destination, but any per-source transformation logic is not portable.
Practical Evaluation Checklist
When trialing MovingLake, run through this list to make sure it fits your stack:
- [ ] Confirm your highest-volume source API is in the catalog and uses the transport you expect (webhook preferred, websocket as backup, polling as fallback).
- [ ] Test fan-out by binding the same source to two destinations (one database, one webhook) and confirm both stay in sync.
- [ ] Force a downstream failure (drop the destination database) and confirm events queue in the dead-letter queue and replay cleanly once the destination recovers.
- [ ] Verify HMAC signing on the webhook destination if you intend to consume events from a custom service.
- [ ] Add a new field to the source API and confirm the destination table gains the column automatically (schema evolution).
- [ ] Measure drift: compare the source API to the destination table after 24 hours of normal load. The platform targets under one minute of drift; if you see more, check the transport selection and rate-limit override.
Security Notes
- All traffic is over TLS. Webhook destinations support optional HMAC-SHA256 signing using a per-destination secret. The signing scheme is documented in the destination config.
- Destination credentials are stored encrypted at rest. The platform does not store raw API responses longer than the configured retention window, and per-source data residency is configurable in the enterprise tier.
- For the database destination, the platform writes with a service role that has table-create privileges. If your destination database uses strict least-privilege roles, you will need to grant the platform DDL rights for the initial table creation, then optionally downgrade.
- For the webhook destination, validate the signature on the receiving side. Treat incoming payloads as untrusted until the HMAC check passes.
FAQ
Q: Is MovingLake open source? A: No. MovingLake is a hosted SaaS with a flat monthly fee. There is no self-hosted edition and the connector logic is not published.
Q: How does MovingLake compare to Fivetran, Airbyte, or Stitch? A: The biggest difference is real-time transport selection. Fivetran and Stitch are batch-oriented (5-minute to 1-hour windows). Airbyte is open source and self-hostable, but its connector logic is also batch-first. MovingLake picks the right transport per source (webhook, websocket, or polling) and fans out a single replayable stream to multiple destinations in near real time.
Q: Does MovingLake support reverse ETL? A: Yes. You can pipe a source stream straight to a CRM or operational system without going through a warehouse first. The founders explicitly position this as an alternative to the data-warehouse-as-control-plane pattern.
Q: How is pricing structured? A: Flat monthly fee, independent of how many destinations you bind a source to. There is no per-event or per-row metering. Exact tiers require contacting sales.
Q: Can I use MovingLake for change data capture from my own database? A: Yes. CDC plugins watch Postgres, MySQL, and a few other engines and stream change events to any destination, including message queues and webhooks. The platform handles schema evolution for the destination automatically.
Q: What happens if a destination is down? A: Events queue in a per-destination retry buffer with exponential back-off and jitter. Optional deduplication prevents the same event from being delivered twice when the destination recovers. Persistent failures land in a dead-letter queue that you can inspect from the dashboard or via the API.
Conclusion
MovingLake is a pragmatic answer to the “we have ten APIs and seven destinations” problem that haunts most mid-stage engineering teams. The combination of per-source transport selection, fan-out pricing, replayable event streams, and built-in schema evolution makes it worth a serious look if your data integration today is a folder of cron jobs and a pager rotation for the inevitable drift outage. The main friction point is the sales-led signup flow — for teams that need self-serve evaluation, that alone may be a deal-breaker. For everyone else, it is one of the cleanest real-time integration services in the YC S22 batch.
Related Posts
dev-tools
Automotive Skills Suite for AI Engineering
Evaluate Automotive Skills Suite for APQP, ASPICE, HARA, safety-plan, and DIA workflows with setup notes, governance risks, and SME review guidance.
5/28/2026
dev-tools
awesome-agentic-ai-zh Roadmap Guide
Explore awesome-agentic-ai-zh as a Chinese agentic AI learning roadmap, with setup notes, track selection, study workflow, and evaluation guidance.
5/28/2026
dev-tools
Baguette iOS Simulator Automation Guide
Set up Baguette for iOS Simulator automation, web dashboards, device farms, gesture input, streaming, and camera testing with Xcode caveats.
5/28/2026